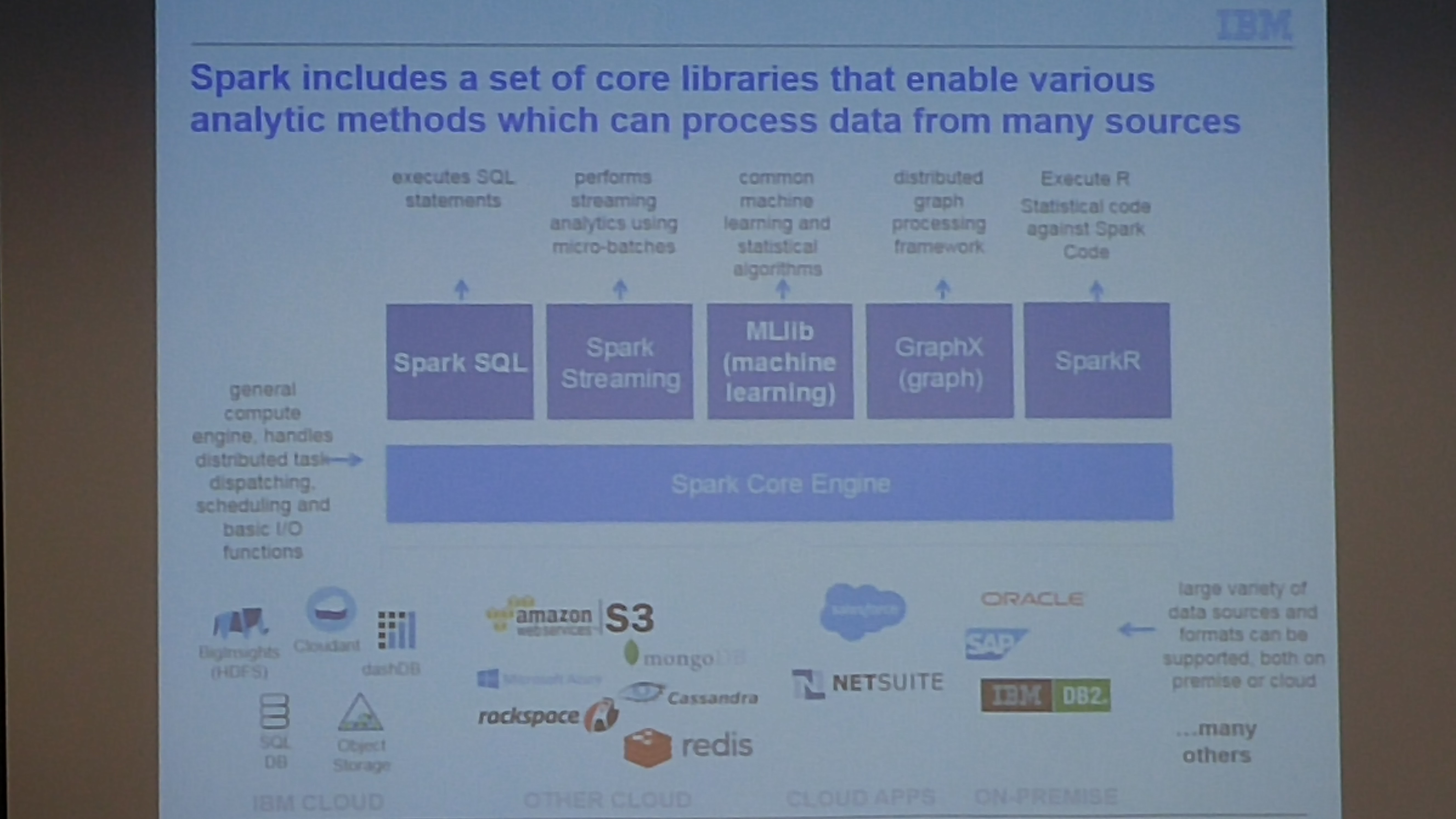
Apache Spark is a general purpose cluster computing platform which extends map-reduce to support multiple computation types including but not limited to stream processing and interactive queries. Last week IBM's Moktar Kandil presented at the Tampa Hadoop and Tampa Data Science Group Joint meetup on the topic of exploring Apache Spark.
Apache Spark for Azure HD-Insight
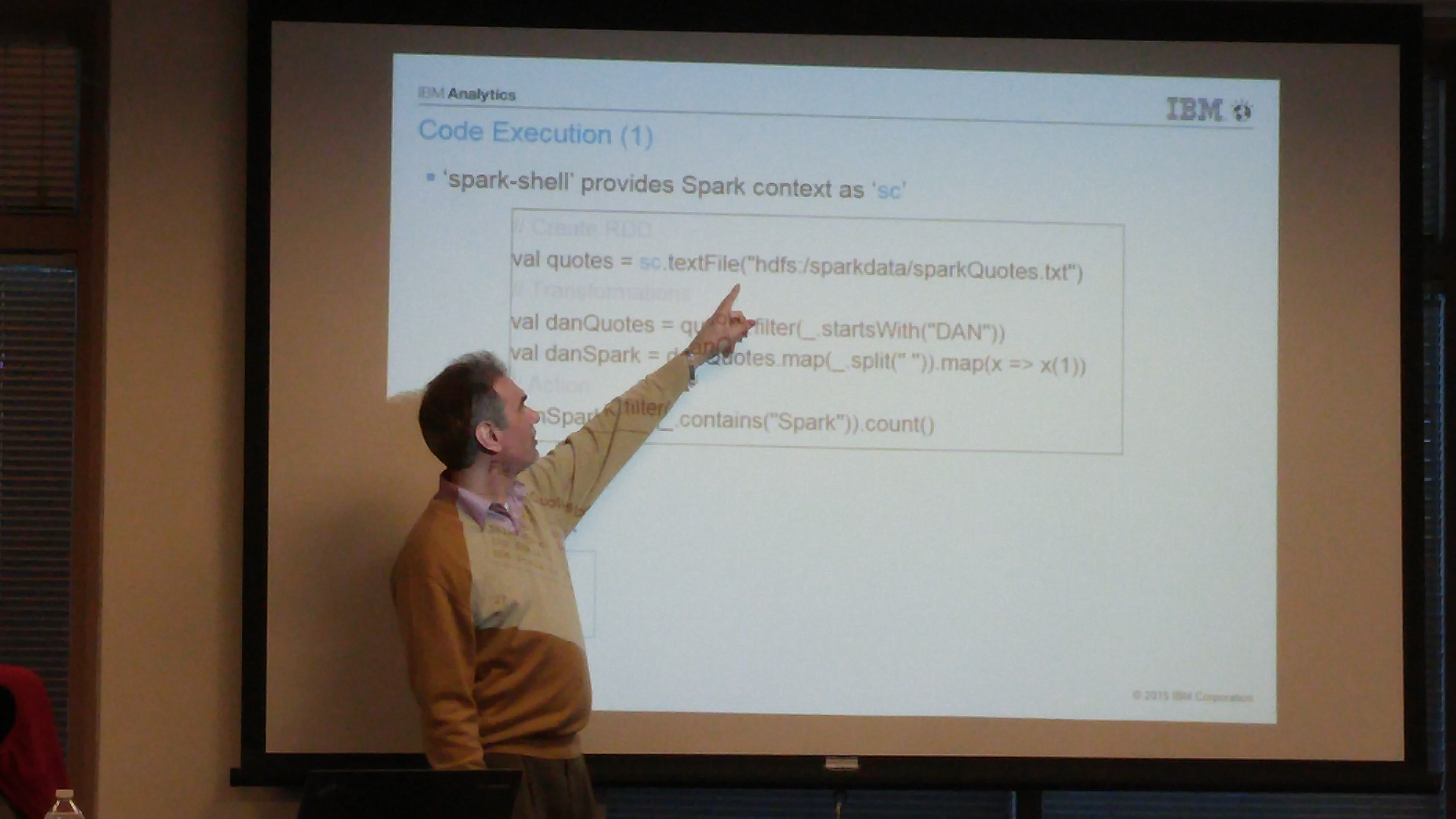
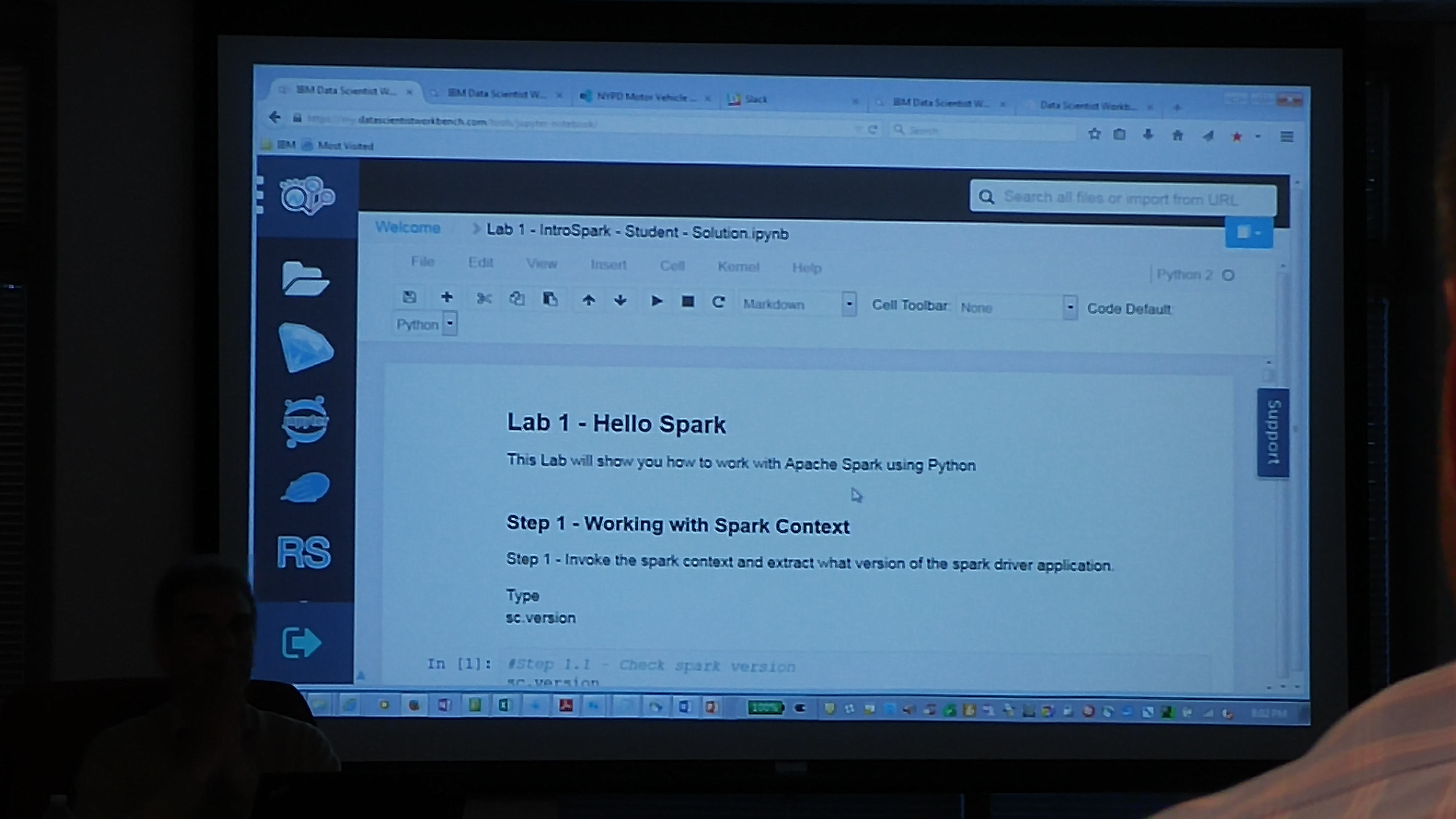
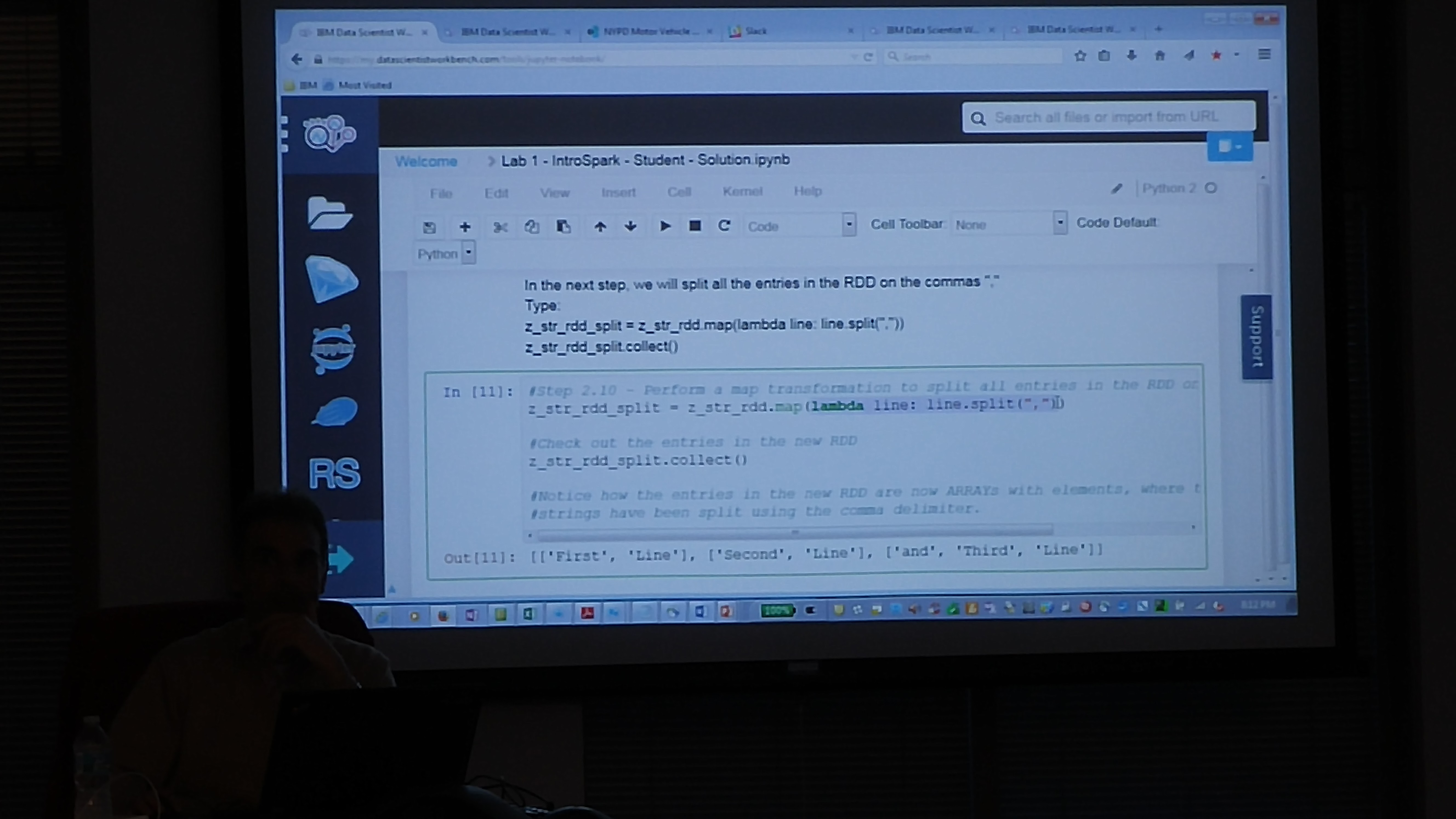
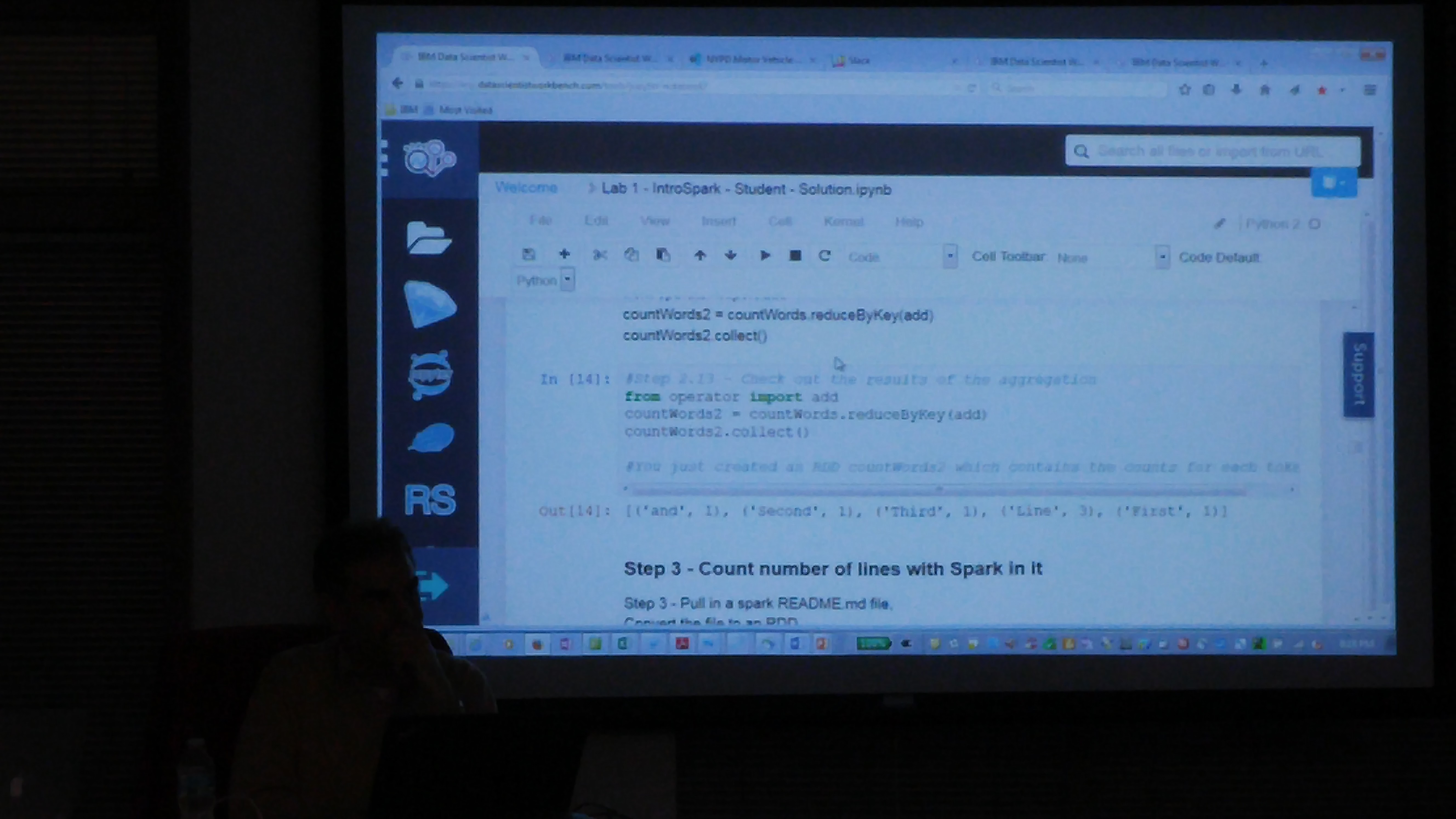
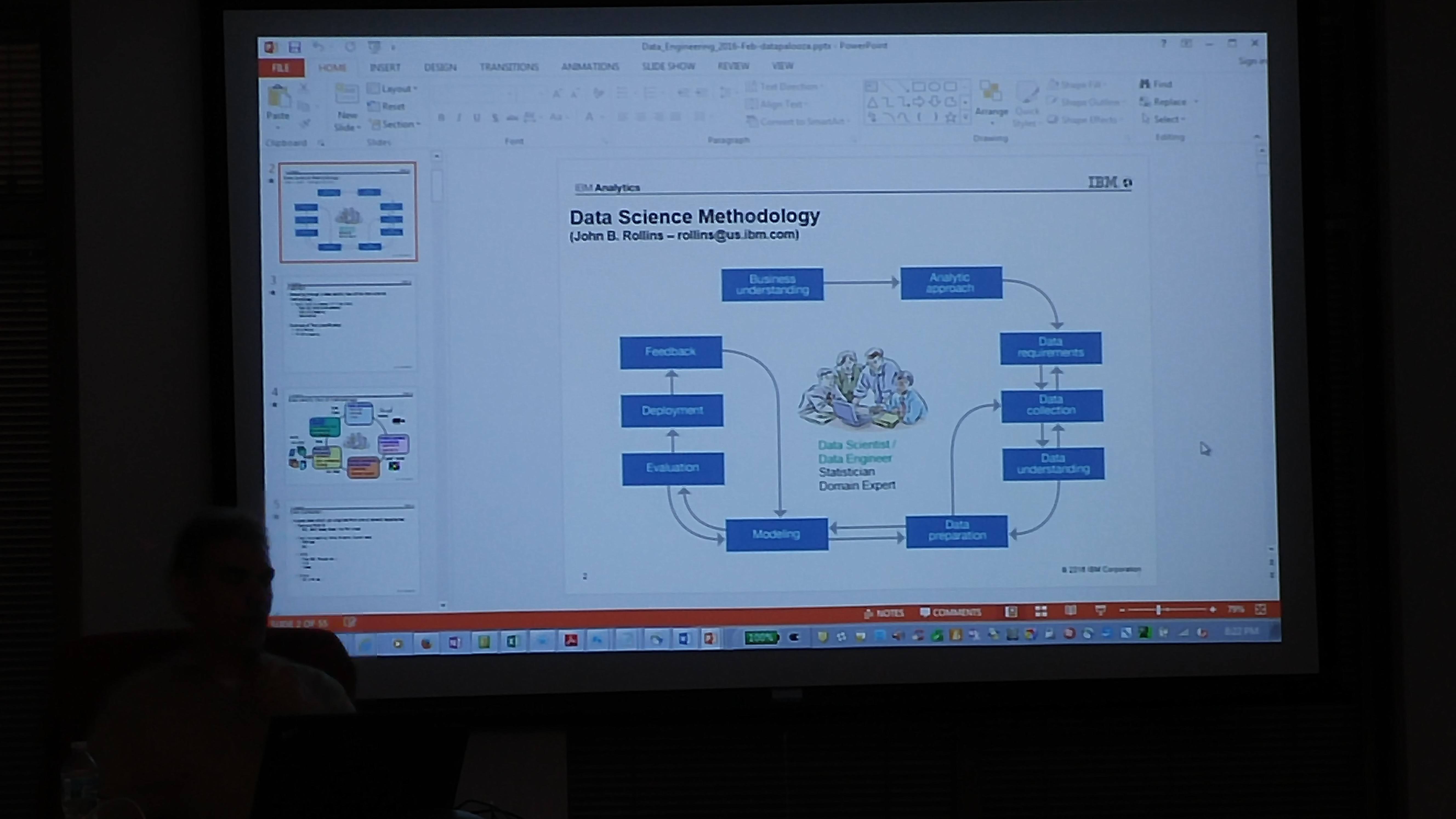
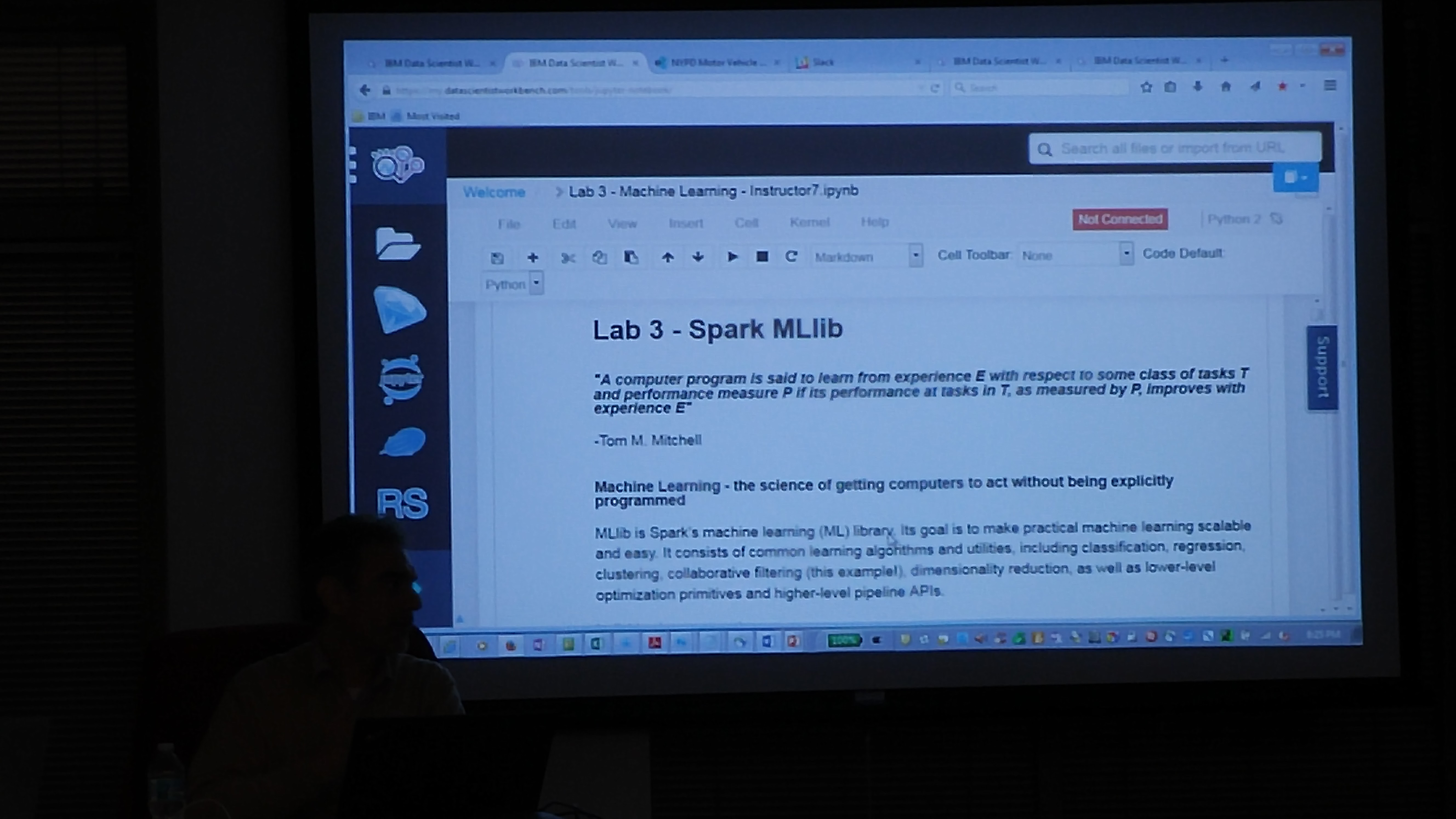
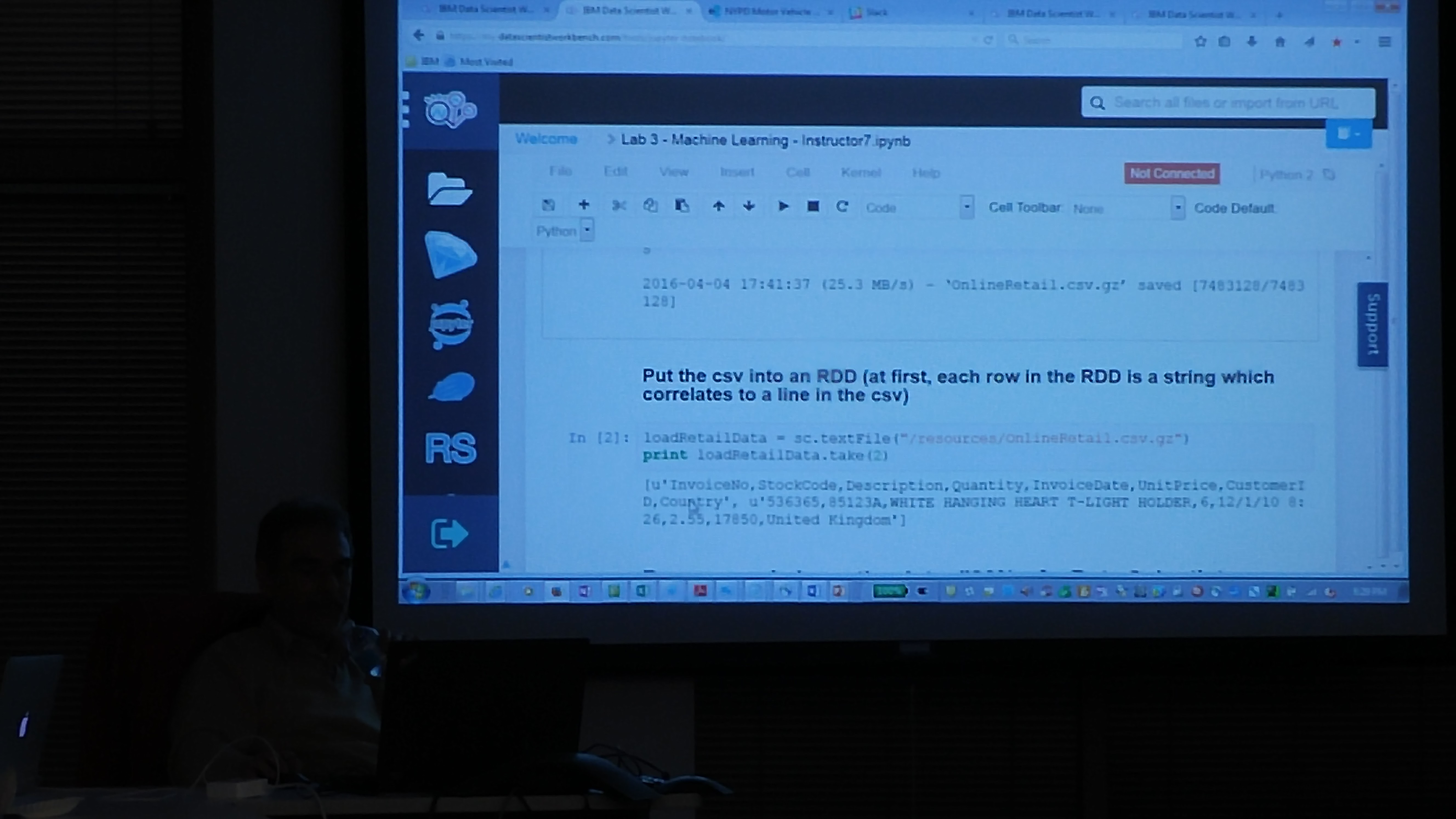
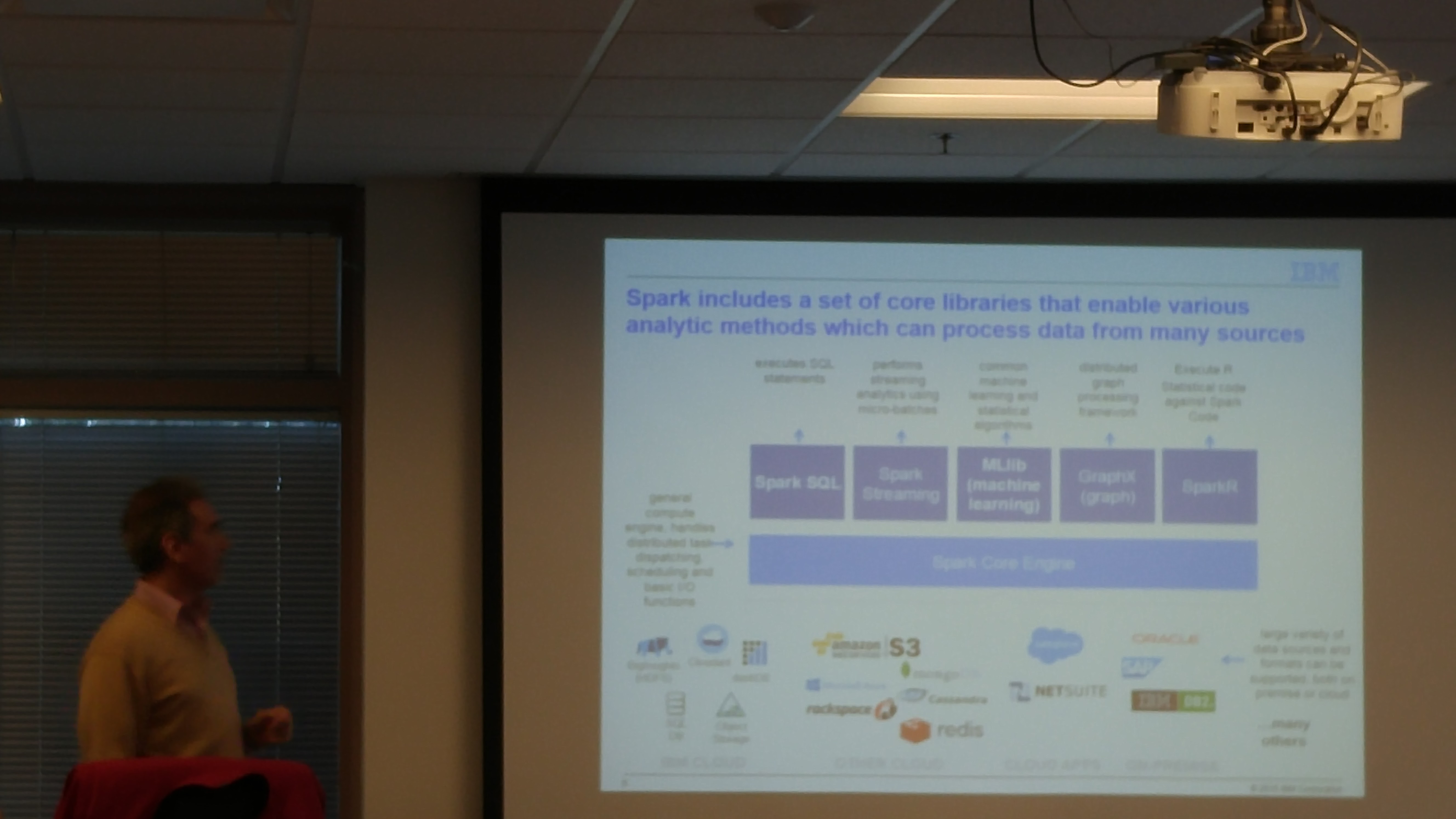
Following are some of the slides discussed in the meetup. To play with the ALS Recommendation engine notebook, please register at www.datascientistworkbench.com which is a free notebook for Apache Spark platform for educational purposes.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Comments are closed.