- Cascades, boosting
- Neural networks, deep learning
- Back-propagation
- Image/text annotation, translation
Dr. Barzilay introduced BoosTexter for the class with a demo on twitter feed. BoosTexter is a general purpose machine-learning program based on boosting for building a classifier from text and/or attribute-value data. It can be downloaded from here while step by step instructions can be found here as part of Assignment 2: Extracting Meaning from Text. The paper outlining BoosTexter is a Boosting-based System for Text Categorization. An Open-source implementation of Boostexter (Adaboost based classifier) can be found here.
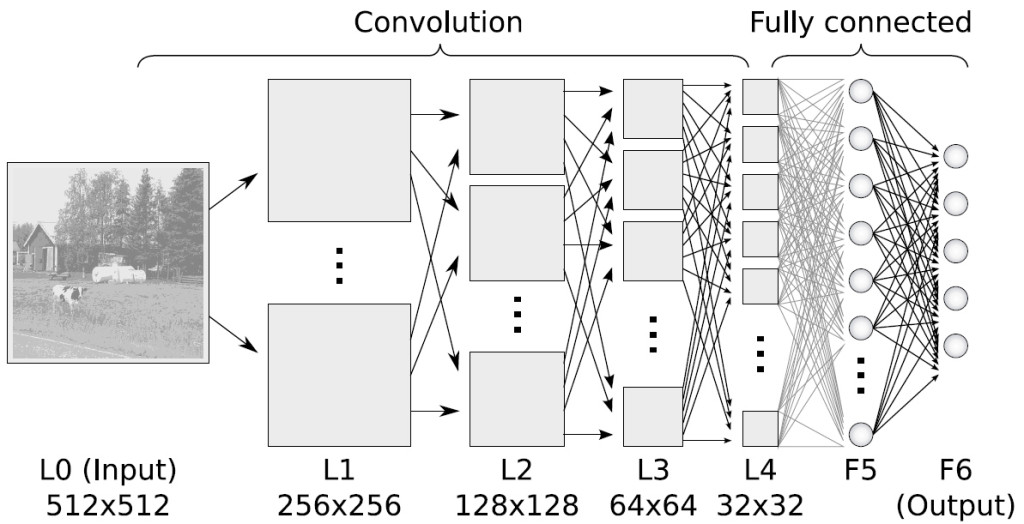
Reference: http://www.ais.uni-bonn.de/deep_learning/
A question was brought up regarding where to get the data from; following are few sources.
- ACL Anthology A Digital Archive of Research Papers in Computational Linguistics
- LDC Catalog https://catalog.ldc.upenn.edu
After the intro to BoosTexter, we jumped into ensemble learning and boosting. Here are some of the pertinent resources to the lecture.
- Boosting Simple Model Selection Cross Validation Regularization
- Introductory lecture - CSE 151 Machine Learning Instructor: Kamalika Chaudhuri
- Fighting the bias-variance tradeoff
Questions like Does ensembling (boosting) cause overfitting? came up and we talked about how Machines read Twitter and Yelp so you don’t have to. I think one of the most relevant resource can be summed up in Foundations of Machine Learning Lecture by Mehryar Mohri Courant Institute and Google Research.
At this point, a detailed discussion about Loss Function was in order. Loss function is the function indicating the penalty for an incorrect prediction but the different kinds of loss functions (or cost functions) such as zero-one loss (standard loss function in classification) or for non-symmetric losses (good vs spam emails classification), or squared loss which is standard loss function in regression. MSR's paper on On Boosting and the exponential loss is a good starting point to follow this topic.
Speaking of Boosting, we reviewed BOOSTING (ADABOOST ALGORITHM) Eric Emer, Explaining AdaBoost Robert E. Schapire and Ensemble Learning. Some of the questions came up like In boosting, why are the learners “weak”?, What is a weak learner?, How to boost without overfitting or Does ensembling (boosting) cause overfitting? and Is AdaBoost less or more prone to overfitting?
Misc topics included, so what happens when you don't have mistakes? Here comes Perceptron Mistake Bounds by Mehryar Mohri, Afshin Rostamizadeh which talks about why the error rate doesn't become zero. How about Extracting Meaning from Millions of Pages, the natural language toolkit NTLK - Extracting Information from Text, Parsing Meaning from Text and of course sickit learn for Ensemble methods
Adaboost Demo
After lunch, Dr. Tommi Jaakkola (Bio) (Personal Webpage) started with the ANN - Neural networks. There was of course the mandatory mention of AI Winter and how neural networks fell out of favor. Dr. Jaakola spoke about Support Vector Machines vs Artificial Neural Networks, What are advantages of Artificial Neural Networks over Support Vector Machines? Neural networks vs support vector machines: are the second definitely superior? etc. A good overview lecture for Neural Networks can be found here.
As Minsky said
[The perceptron] has many features to attract attention: its linearity; its intriguing learning theorem; its clear paradigmatic simplicity as a kind of parallel computation. There is no reason to suppose that any of these virtues carry over to the many-layered version. Nevertheless, we consider it to be an important research problem to elucidate (or reject) our intuitive judgment that the extension is sterile.
-Quote from Minsky and Papert’s book, Perceptrons (1969):
The topic quickly converged to learning in Multi-Layer Perceptrons - Back-Propagation and forward propogration. Iin order to cover Stochastic gradient descent, Non-linear classification, neural networks, and neural networks (multi-layer perceptron, this will give you a good overview. and of course props for Minsky.
The rationale essentially is that Perceptrons only be highly accurate for linearly separable problems. However, Multi-layer networks (often called multi-layer perceptrons, or MLPs) can work in case of any complex non-linear target function. The challenge we see in the multi-layer networks is that it provides no guarantee of convergence to minimal error weight vector. To hammer in these ideas, Exercise: Supervised Neural Networks is quite helpful. Few more relevant resources.
- Single Layer Neural Networks Hiroshi Shimodaira
- What is the difference between back-propagation and forward-propagation?
- Neural Networks Tutorial
- The Back-propagation Algorithm
- Vector Calculus: Understanding the Gradient (or derivative)
- Lecture 11: Feed-Forward Neural Networks
Next topic was of Feature Scaling; What is feature scaling? A question posed was that if Feature-scaling is applied to the data before input into the artificial neural network will make the network converge faster. This is well defined here in coursera Gradient Descent in Practice - What is Feature Scaling. This brought up the point of How to “undo” feature scaling/normalization for output?, and How and why do normalization and feature scaling work?
The concluding topic of the day was Convolution neural network.Convolutional Neural Networks (CNN) are biologically-inspired variants of MLPs. There has been amazing things done by the use of CS231n Convolutional Neural Networks for Visual Recognition.
There has been immense interest in topics like Large-scale Learning with SVM and Convolutional Nets for Generic Object Categorization, ImageNet Classification with Deep Convolutional Neural Networks, Convolutional Kernel Networks and how convolution networks can help generate text for images. Here are some of the relevant papers.
- CNN Features off-the-shelf: an Astounding Baseline for Recognition
- Text Understanding from Scratch
- END-TO-END TEXT RECOGNITION WITH CONVOLUTIONAL NEURAL NETWORKS
- Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts
- Convolutional Neural Networks for Sentence Classification
- Visualizing and Understanding Convolutional Network
- Caffe Deep learning framework by the BVLC
- A picture is worth a thousand (coherent) words: building a natural description of images
- Show and Tell: A Neural Image Caption Generator
- Generating Text with Recurrent Neural Networks
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Building Fast High-Performance Recognition Systems with Recurrent Neural Networks and LSTM
- LONG SHORT-TERM MEMORY
- Convolutional Neural Net Image Processor Link
Looking forward to tomorrow's class!
