On the final day (day 5) the agenda for the MIT Machine learning course was as follows:
- Generative models, mixtures, EM algorithm
- Semi-supervised and active learning
- Tagging, information extraction
The day started with Dr. Jakkola's discusion on parameter selection, generative learning algorithms, Learning Generative Models via Discriminative Approaches, and Generative and Discriminative Models. This led to the questions such as What are some benefits and drawbacks of discriminative and generative models?. What is the difference between a Generative and Discriminative Algorithm and how to learn from Little data - Comparison of Classifiers Given Little Training.
One of the reasons I truly enjoyed the course is because you always learn something new working with practioners and participating academics. One of such topics was Machine Learning Based Missing Value Imputation Method for Clinical Dataset. We revisited Missing Data Problems in Machine Learning, Imputation of missing data using machine learning techniques, class imbalance problem, Machine Learning from Imbalanced Data Sets 101, and DATA MINING challenges FOR IMBALANCED DATASETS
Feature reduction and data transformation is really helpful for model building. Dr. Jakkolla talked about how to architect feature structures. We did review of ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches, Feature Set Embedding for Incomplete Data before moving on to Naive Bayes.
Since Naive Bayes classifiers (excellent tutorial) performs so well, we had to find some problems with it! Hence Naive Bayes with unbalanced classes, Naive-Bayes classifier for unequal groups, Tackling the Poor Assumptions of Naive Bayes Text Classifiers, Naive Bayes for Text Classification with Unbalanced Classes, Class Imbalance Problem, Techniques for Improving the Performance of Naive Bayes for Text Classification, and Tackling the Poor Assumptions of Naive Bayes Text Classifiers. The elephant in the room question was when does Naive Bayes perform better than SVM?
Transfer learning was also something I needed a refresher on. As stated
When the distribution changes, most statistical models need to be rebuilt from scratch using newly collected training data. In many realworld applications, it is expensive or impossible to recollect the needed training data and rebuild the models. It would be nice to reduce the need and effort to recollect the training data. In such cases, knowledge transfer or transfer learning between task domains would be desirable.
From: http://www1.i2r.a-star.edu.sg/~jspan/publications/TLsurvey_0822.pdf
Dr. Jakkola then did an final review / sum of of Supervised techniques (classification, rating, ranking), unsupervised (clustering, mixture models), and Semi-supervised (making use of labelled and unlabelled by means of clustering) along with Generative techniques (naive bayes) and Discriminative techniques (Perceptron /PA, SVM, Boosting, Neural Networks, Random Forests) and emphasized the fact that Discriminative analysis is performance driven.
Then someone asked, Which is the best off-the-shelf classifier? i.e. when I have to do least work myself. SVM is one of the obvious choices, but here is some food for thought as well.
If we bag or boost trees, we can get the best off-the-shelf prediction available. Bagging and Boosting are ensemble methods that combine the fit from many (hundreds, thousands) of tree models to get an overall predictor.
http://faculty.mccombs.utexas.edu/carlos.carvalho/teaching/Sec4_Trees.pdf
Here is a good tutorial on Ensemble learning approach - Committee-based methods Bagging - increasing stability Boosting - ”Best off-the-shelf classification technique” ”Fate is a great provider!” - Random Forests etc. and this one explaining the Success of AdaBoost and Random Forests as Interpolating Classifiers. We discussed this couple of days ago, but still a good reference. CNN Features off-the-shelf: an Astounding Baseline for Recognition. Dr. Jakkolla emphasized that when it comes to Neural networks, they are highly flexible, hence time consuming; Test time efficient and difficult to train. For Scaling Machine Learning, this is a great resource.
Stochastic gradient descent is a gradient descent optimization method for minimizing an objective function that is written as a sum of differentiable functions. After a mandatory gradient descent / ascent talk, we spoke again about scalability, and Scalable Machine Learning. Here are couple of good reference of Scaling Up Machine Learning Parallel and Distributed Approaches, and Scalable Machine Learning From a practitioner's perspective, Apache Mahout helps build an environment for quickly creating scalable performant machine learning applications. Here is a good reference on Scalable Machine Learning - or - what to do with all that Big Data infrastructure.
Dropout training technique is something else I learned about during this class. Preventing feature co-adaptation by encouraging independent contributions from different features often improves classification and regression performance. Dropout training (Hinton et al., 2012) does this by randomly dropping out (zeroing) hidden units and input features during training of neural networks. Dropout: A Simple Way to Prevent Neural Networks from Overfitting and ICML Highlight: Fast Dropout Training are good resources. Dr. Jakkolla know these techniques so well, he discussed spectral embedding / Laplacian Eigenmaps) as one method to calculate non-linear embedding. Laplacian eigenmaps for dimensionality reduction and data representation, Manifold learning and Nonlinear Methods are good follow up places.
We surveyed diverse topics such as Dimensionality reduction, Dimensionality Reduction Tutorial, Covariance Matrix and answered questions like What is usage of eigenvectors and eigenvalues in machine learning?, What are eigenvectors and eigenvalues? and PCA.
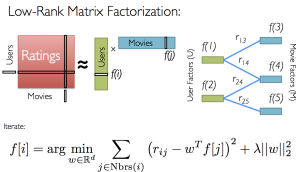 Image Courtesy AMPCAMP Berkeley
Image Courtesy AMPCAMP Berkeley
The afternoon session started with Dr. Barzilay Recommender system talk. There were various topics discussed including Slope One - Cold start - Robust collaborative filtering and I like what you like. dr. Barzilay talk about cases when recommendations may be similar in one way, and different in other ways. Global vs. Local comparisons, matrix factorization techniques for recommender systems, using SVD and finally the quentisential netflix challenge.
Some key resources included The “Netflix” Challenge – Predicting User preferences using: -Average prediction -Item-based Collaborative filtering -Maximum Margin Matrix Factorization, GroupLens: An Open Architecture for Collaborative Filtering of Netnews, Explaining Collaborative Filtering Recommendations, Collaborative Filtering Recommender Systems, Item-to-Item Collaborative Filtering and Matrix Factorization , The BellKor solution to the Netflix Prize
Last but not least, Dr. Barzilay talked about Why netflix never implemented the algorithm and why simple but scalable approaches are better choices than their complex and resource intensive counterparts.

It was a brilliant class. Lots of networking and learning. Thanks to our instructors for their hard work, and diligence in getting the knowledge and concepts across.. The class ended with the certificate distribution and Q&A session.
I plan to implement these ideas in practice. Happy Machine Learning!
Miscellaneous Links.
- Recognizing hand-written digits- scikit-learn.org/0.11/auto_examples/plot_digits_classification.html
- An Introduction to Machine Learning Theory and Its Applications: A Visual Tutorial with Examples www.toptal.com/machine-learning/machine-learning-theory-an-introductory-primer
- Machine Learning 101: General Concepts www.astroml.org/sklearn_tutorial/general_concepts.html
- Linear Algebra for Machine Learning machinelearningmastery.com/linear-algebra-machine-learning/
- Develop new models to accurately predict the market response to large trades. https://www.kaggle.com/c/AlgorithmicTradingChallenge
- ML exams
- http://www.cs.cmu.edu/~guestrin/Class/10701/additional/
- http://www.cs.cmu.edu/~guestrin/Class/10701/additional/final-s2006.pdf%20
- http://www.cs.cmu.edu/~guestrin/Class/10701/additional/final-s2006-handsol.pdf
