“May the queries flow, and the pager stay silent. —Traditional SRE blessing”
Like *.js, DevOps / SRE isn’t completely immune from the dilemma of choice, or confusion as a service as some would like to call. Should it be Nagios or Zabbix or Cacti or Zenoss or Borgmon? Regardless of which tool one decides for monitoring usage, most practical guides to alerting at scale would classify Service Level Agreements (SLA) as economic incentives, Service Level Objectives (SLO) as goals, and SLI (Service Level Indices) as measurements; an ROI metrics driven approach which doesn't necessarily keep your focus on eliminating the false positives by analyzing, identifying and eliminating outliers. In “Identifying Outages with Argos, Uber Engineering’s Real-Time Monitoring and Root-Cause Exploration Tool”, Dr. Franziska Bell outlines the importance of Building and integrating an Anomaly Detection Algorithm with the traditional SRE approaches to build an intelligent monitoring and alerting platform.
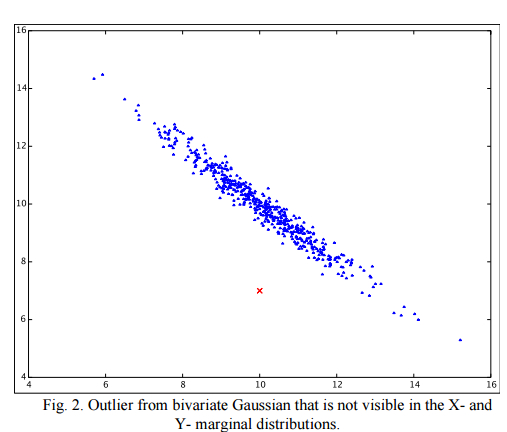
Anomaly Detection in Application Performance Monitoring Data Thomas J. Veasey and Stephen J. Dodson
Outlier detection in operational data is not unique to Uber, Tracking down the Villains: Outlier Detection at Netflix describes finding a Rabbit in a snowstorm by using one of the classical algorithms Density-Based Spatial Clustering of Applications with Noise (DBSCAN). This in a nutshell helps measuring the stddev against a n minute moving average and alert based on that, intelligent alerting lives. SVM approaches has also been applied to temporal data and sometimes a combination of multiple approaches provide a better solution. For instance, in case of Netflix there are two outlier detection approaches which complement each other; density-based clustering (RAD) which is which is used to perform RPCA (Robust principal component analysis) and estimates thresholds. However, since RAD needs multiple cycles, it is not suitable for real-time analytics which require short time frames. In the case of DSSCAN, Netflix sacrifices accuracy for performance and have a safety net of RPCA in place.
In case when “Achieving Rapid Response Times in Large Online Services” is the key, it is important to get the alerts right. Outlier detection comes in various varieties including but not limited to statistical testing, depth, deviation and distance based approaches, as well as statistical models of density and high dimensionality. Time series analysis makes this more interesting. To be clear, the focus here is not necessary fraud, intrusion, threats, and defect detection, but merely monitoring the systems against their baseline threshold time frames.
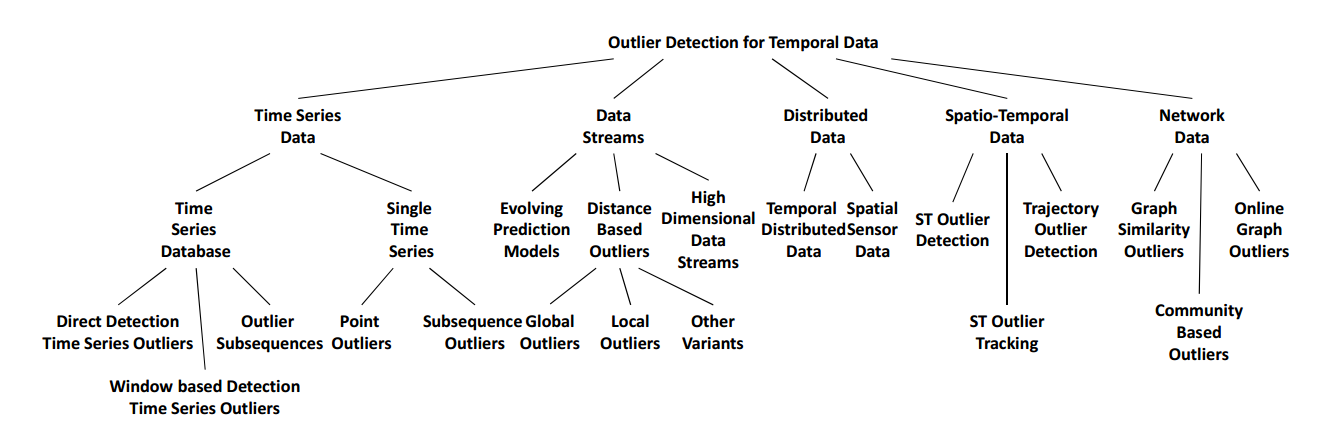
Reference: Outlier Detection for Temporal Data: A Survey Manish Gupta, Jing Gao, Member, IEEE, Charu C. Aggarwal, Fellow, IEEE, and Jiawei Han, Fellow, IEEE
Machine learning based approaches, as part SRE practices is part of a larger Maturity model. To borrow the example from Site Reliability Engineering: How Google Runs Production Systems, in the beginning we start with the following:
- No failover - No automation Database master is failed over manually between locations.
- Externally maintained system-specific automation
- Externally maintained generic automation
- Internally maintained system-specific automation
- Systems that don’t need any automation The database notices problems, and automatically fails over without human intervention.
Systems Self automation i.e. prediction of potential database problems, based on the overall system health and therefore predicting an automatically fails over without human intervention would be the next step in this maturity model with the help of machine learning techniques. Better Living through Statistics: Monitoring Doesn't Have to suck makes an excellent case for intelligent site reliability engineering at linux.conf.au 2016 slides. Having argued that, a window based online model might be the Holy Grail, but Dieter Plaetinck also make a strong case for simplicity and familiarity in this space. The availability of Commercial tools such as this and this also help getting the ball rolling while you explore techniques such as Secure because Math: A deep-dive on Machine Learning-based Monitoring in-depth and analyze data further.
Outlier analysis and machine learning based fine tuning the DevOps/SRE metrics is in congruence with what Rob Ewaschuk stated in his philosophy of alerting
-
Every time my pager goes off, I should be able to react with a sense of urgency. I can only do this a few times a day before I get fatigued.
-
Every page should be actionable; simply noting "this paged again" is not an action.
-
Every page should require intelligence to deal with: no robotic, scriptable responses
This leads to discussing SRE from a more traditional perspective. My recent reading Site Reliability Engineering, How Google Runs Production Systems is an excellent addition among the limited list of must-read books for all dev-Ops / Site reliability engineers, who love to keep their production systems humming smoothly, with reliable monitoring and instrumentation. This terse yet comprehensive book includes technical details along with the lessons learned (yes, including failures!), the associated thought processes, organizational / team goals, and the principles behind the proposed approaches.

This ~550 page manuscript by Betsy Beyer, Chris Jones, Jennifer Peto, and Niall Richard Murphy is essentially a cohesive collection of essays following a homogenous theme of developing infrastructure as code, and keeping reliability as their key focus. The central theme of the book can be summarized by Joseph Bironas, an SRE as follows:
“If we are engineering processes and solutions that are not auto‐matable, we continue having to staff humans to maintain the sys‐ tem. If we have to staff humans to do the work, we are feeding the machines with the blood, sweat, and tears of human beings. Think The Matrix with less special effects and more pissed off System Administrators.”
Site Reliability Engineering, How Google Runs Production Systems is divided into 5 parts namely Introduction, Principles, Practices, Management, and Conclusion.
The primer compares and contrasts SysAdmin’s Approach to Service Management with Google’s Approach to Service Management. It describes Tenets of SRE as SRE team being responsible for the availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning of their service(s). Moving forward, we see how the production environment looks like at Google, from the Viewpoint of an SRE with an overview of networking, storage, hardware, and the System Software That “Organizes” the Hardware. We get a fleeting glimpse of Google’s Software Infrastructure, and Development Environment before jumping into the principles.
The principles section starts with the idea of embracing and managing risk. This is a discipline which most organizations lack. Working with Marty Abbot and Geoff Kershner has taught me a thing or two about the Availability matrix as shown below. This basic understanding of what three 9's downtime isn’t nearly as common as you'd like it to be.
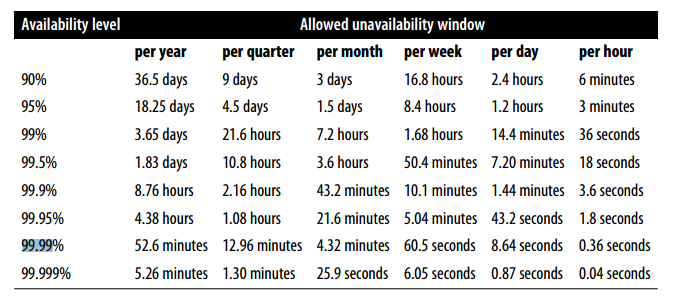
Authors further continue the discourse around measuring service risk as well as risk tolerance of services and the idea of building error budgets. Error budgets define the acceptable level of failure for a service, over some period. Software fault tolerance Testing, Push frequency and Canary duration/size are deemed key factors for motivation around error budgets. Next chapter discusses SLA (service level agreement) with its economic incentives, SLO (Service Level Objective) as a goal, and SLI (Service Level Indicator) as a measurement. We later see how these indicators are used in Practice.

Yet another pleasant surprise follows! This particular section also deals with firefighting aspect of everyday dev-ops operations and talks about Eliminating Toil. It is defined quite well as “manual, repetitive, automatable, tactical, devoid of enduring value, that scales linearly as a service grows” with some tips on how to get rid of the false sense of urgency we all at devops have learned to live with.
“Toil is the kind of work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows”
Next chapter deals with monitoring of distributed systems, Setting Reasonable Expectations for Monitoring, defines Symptoms Versus Causes, Black-Box Versus White-Box testing and describe the Four Golden Signals for monitoring as latency, traffic, errors, and saturation. With emphasis on long term monitoring, we jump into an overview of how Automation evolved at Google. One key theme of the book is the emphasis on core values; the Value of Automation, the Value for Google SRE, and a case for Use Cases for Automation are emphasized as much as it is recommended to automate Yourself Out of a Job. In this chapter we learn about Borg, the Warehouse-Scale Computer. While defining Reliability Is the Fundamental Feature, authors discuss how Release Engineering works and what is a Role of a Release Engineer in the organizational eco system is.
Example of a Failure: In 2005, Google’s global DNS load- and latency-balancing system received an empty DNS entry file as a result of file permissions. It accepted this empty file and served NXDOMAIN for six minutes for all Google properties. In response, the system now per‐ forms a number of sanity checks on new configurations, including confirming the presence of virtual IPs for google.com, and will continue serving the previous DNS entries until it receives a new file that passes its input checks. In 2009, incorrect (but valid) data led to Google marking the entire Web as containing malware [May09]. A configuration file containing the list of suspect URLs was replaced by a single forward slash character (/), which matched all URLs. Checks for dramatic changes in file size and checks to see whether the configuration is matching sites that are believed unlikely to contain malware would have prevented this from reaching production.
In the Philosophy section, we deal with SDLC related aspects of the SRE including Continuous Build and Deployment, and Configuration Management. Even though light at details, this is not really the core focus of the book. We still see some practical issues being addressed such as code-control-syndrome “I Won’t Give Up My Code!” and “Negative Lines of Code” Metric.
Chapter 10 on Practical Alerting from Time-Series Data introduces Borgmon. Borg is a cluster manager taking care of accepting, scheduling, starting, stopping, restarting and monitoring hundreds of thousands of jobs submitted by thousands of applications on behalf of various services and running on a variable number of clusters each comprising up to tens of thousands of servers. It is discussed in detail in the research paper titled “Large-scale cluster management at Google with Borg” (PDF)
Monitoring and Alerting sans false positives is a difficult balancing act which google has mastered with the Borgmon. Follow up with instrumentation of applications, collection of Exported Data, Storage in the Time-Series Arena, Rule Evaluation to the extent of Sharding the Monitoring Topology for improved performance, authors break the items down into practicalities of Black-Box Monitoring and how to maintaining the Configuration effectively. Next chapter deals with the bane of every devops existence, the necessary evil of Being On-Call followed by effective Troubleshooting, tips on what to Do When Systems Break, Test/Change/Process-Induced Emergency with incident management and postmortem.
Google prides itself on data driven approaches, tracking outages and resting for Reliability comes hand in hand Testing at Scale. The book provides us Auxon Case Study with Project Background and Problem Space, defines Intent-Based Capacity planning within the context and then emphasizes on fostering Software Engineering practices in SRE. Moving forward we discuss practical aspects of load balancing approaches at the Frontend including Load Balancing Using DNS and Load Balancing at the Virtual IP Address, followed by Load Balancing in the Datacenter and Load Balancing Policies. With 100 billion searches per month, google understands a thing or two about load handing and how to optimize it with Per-Customer Limits, Client-Side Throttling, Criticality, Utilization Signal, how to handling Overload Errors, and the associated Load from Connections.
Progressive back off, Connection Resiliency, and transient fault handling are discussed in consort with cascading Failures. Cascading failure is a failure that grows over time as a result of positive feedback. Preventing server overload in the case of such failure with slower startup, Cold Caching and testing as well as testing for Cascading Failures is followed by the need of managing critical state. Taking on to distributed systems, authors briefly touched about quorums and consensus, however there is a lot more to distributed systems timing Model, Interprocess Communication, Failure Modes and detectors, Leader Election and Time In Distributed Systems Given the byzantine generals benefit of doubt, this chapter justifiable addresses how Distributed Consensus Work, and what are the System Architecture Patterns for Distributed Consensus. This comes with a cost (no free lunch theorem?) and the associated performance hit of distributed consensus, Deployment of Distributed Consensus-Based Systems and last but not least monitoring the Distributed Consensus Systems. Furthermore, the practical aspects of Distributed Periodic Scheduling with Cron, and Idempotency leads to introduction of Data Processing Pipelines (ETL) and data integrity with Google Workflow are discussed in avid detail.
The last chapter in this section is about team collaboration and human coordination aspects of Reliable Product Launches at Scale. Authors discuss Launch Coordination Engineering, Setting Up a Launch Process, Developing a Launch Checklist, Selected Techniques for Reliable Launches, and Development of LCE (special team within Site Reliability Engineering: the Launch Coordination Engineers).
Next section focuses on team building, and managing SREs where authors talk about initial learning experiences, and creating stellar reverse engineers and improvisational thinkers and guidelines for aspiring on-callers. As a true field manual, we are taught to deal with interrupts, techniques to manage operational load, and driving the change. Communication and collaboration in SRE, evolving SRE engagement mode and practical examples of production readiness reviews are discussed followed by lessons learned from other industries such as preparedness and disaster testing, postmortem culture, automating away repetitive work and operational overhead and structured and rational decision making.
In appendix, the book contains several great example documents such as Example Incident State Document, Example Postmortem, and Example Production Meeting Minutes. In closing, even though it is light on actual toolset used, I would classify this book as one of the best contemporary readings on the topic. May be v2 will address machine learning aspects of devops.
References & Further Reading
- What algorithm should I use to detect anomalies on time-series?
- Outlier Detection for Temporal Data: A Survey
- Secure because Math: A deep-dive on Machine Learning-based Monitoring
- Outlier Detection at Netflix (netflix.com)
- PRACTICAL FAULT DETECTION & ALERTING. YOU DON'T NEED TO BE A DATA SCIENTIST
- A Deep Dive into Monitoring with Skyline by Abe Stanway
- Sumo Logic Unveils Outlier Detection and Predictive Analytics to Augment Machine Learning and Anomaly Detection Capabilities
- Detecting and scoring anomalies with calibrated probabilistic models
- Anomaly Detection: Approaches and Challenges
- Anomaly Detection in Application Performance Monitoring Data Thomas J. Veasey and Stephen J. Dodson
- Big Data Outlier Detection, for Fun and Profit Alex Woodie
- Non-intrusive Anomaly Detection with Streaming Performance Metrics and Logs for DevOps in Public Clouds: A Case Study in AWS
- What We Talk About When We Talk About Distributed Systems
- Marcos K. Aguilera. 2010. Stumbling over consensus research: misunderstandings and issues. In Replication, Bernadette Charron-Bost, Fernando Pedone, and André Schiper (Eds.). Springer-Verlag, Berlin, Heidelberg 59-72.
Keywords: temporal outlier detection, time series data, data streams, distributed data streams, temporal networks, spatiotemporal outliers, applications of temporal outlier detection, network outliers
