If I have to rate typical conversations with machine learning enthusiasts, following queries usually rank at the top:
- "How do I pick an algorithm for my dataset?"
- "How do I know which one is the right algorithm to choose for my problem?"
- "Does logistic regression makes my dataset looks big?"
Well, maybe not that last one, but you see what I mean. One fundamental principle in Machine Learning and Data Science methods is that randomly applying methods and hoping for the best is never a good strategy. Knowing your data, and the underlying fundamentals of the algorithms applied to this dataset are positively correlated with how accurate, meaningful, and insightful you'd like your results to be. There is a world of wrong one can do by creating incorrect models. It is so important now more than ever because with modern machine learning libraries, and amazing toolsets like scikit learn, theano etc, it is easy to fool oneself into thinking we are using the right classifier which in reality might not be the case. That is why there is quite some value put into implementing your own algorithms from scratch. Kotthoff et al said it quite well:
The systems that do algorithm selection usually justify their choice of a machine learning methodology (or a combination of several) with their performance compared to individual algorithms and do not critically assess the real performance – could we do as good or even better by using just a single algorithm instead of having to deal with portfolios and complex machine learning?
One way to select an algorithm is by way of a loose machine learning algorithmic classification decision tree, based on a functional needs basis such as:
- Like to predict quantities - Regression problem
- Outliers, Fraudulent and Novel values - Anomaly detection
- Exploring Features, Relationships - Dimentionality Reduction
- Discover Structure and Predict Categories - Classification and Clustering (Unsupervised)
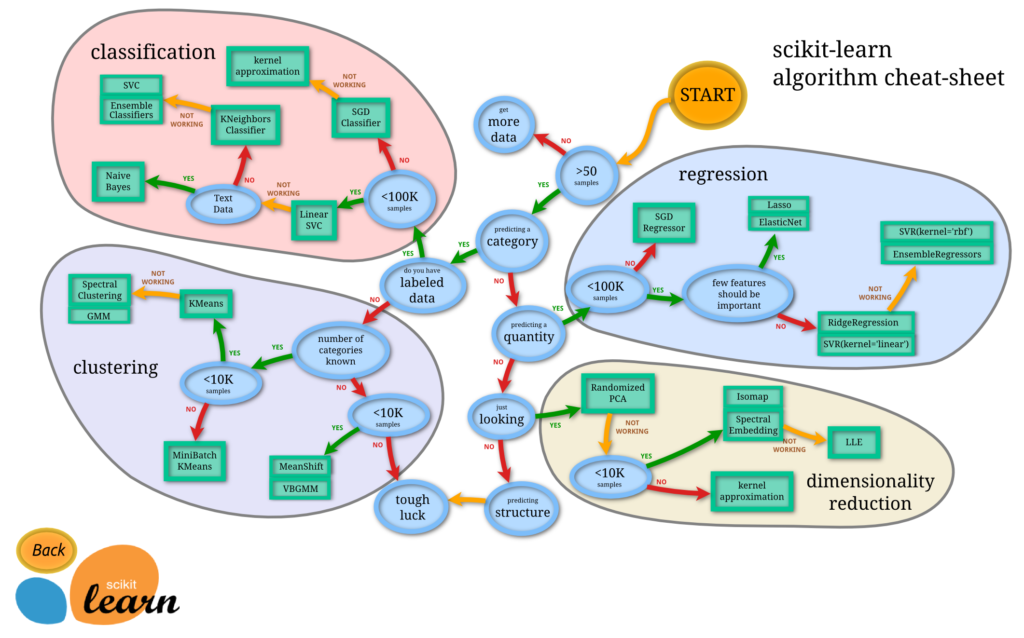
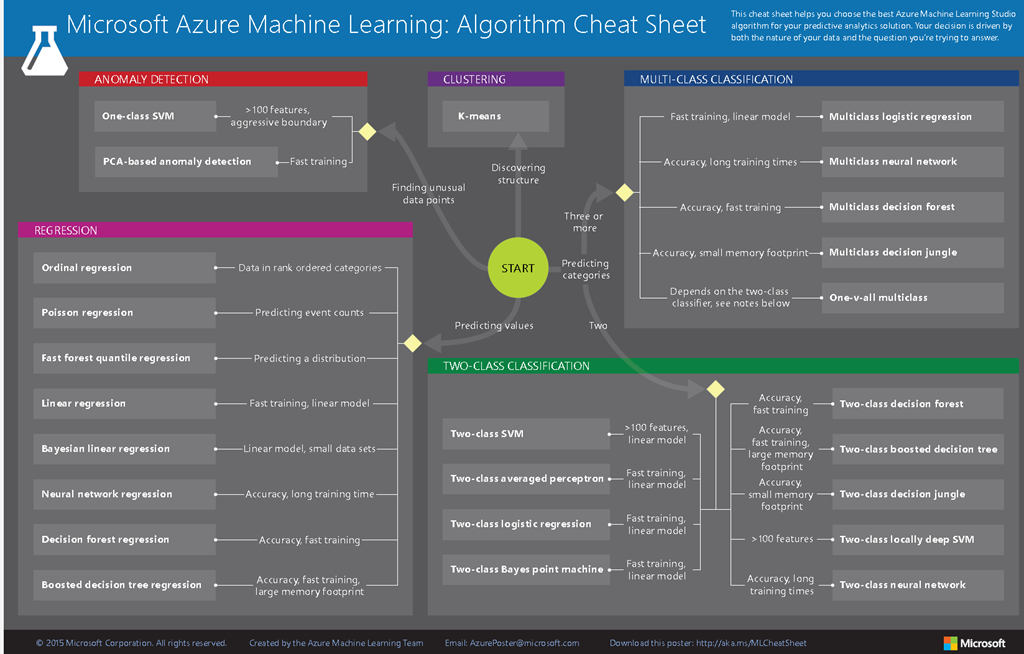
After this very basic selection, you'd also need to consider the type of your model, size of your dataset, training time, accuracy, number of features, etc. In some verticals, there are guidelines available for selection of appropriate ML classifier. To get more detailed, there are couple of in-depth interactive info-graphics which discuss the algorithms in details such as scikit-learn's Machine Learning Map and Azure ML Studio.
In the following Overview diagram of Azure Machine Learning Studio capabilities, the so-called cheat-sheet provides information on different algorithms offered as part of Azure machine learning studio, along with their corresponding brief SWOT analysis.
Even though these worksheets are vendor / library oriented, they provide value in understanding and eventually implementing algorithms, which is a crucial part of machine learning lifecycle and data science pipeline. In Academia, Machine learning is deemed as an established method of selecting algorithms to solve hard search problems. May be one day we can also use it to find the the right machine learning algorithm too.
Recursion level, inception.
References and Further Reading
- How to choose algorithms for Microsoft Azure Machine Learning.
- A-Z list of Machine Learning Studio modules
- Machine Learning Algorithms for Classification
- List of machine learning concepts
- Choosing a Machine Learning Classifier
- Comparing supervised learning algorithms
- An Empirical Comparison of Supervised Learning Algorithms
- Kaggle Forum - Table comparing supervised learning algorithms
