Microsoft Machine Learning and Data Science Summit promised to connect Big Data engineers, Data Scientists, Machine Learning practitioners and managers to share best practices, to Dive deep & learn, and to facilitate Think big & execute fast ideas. In my experience, the summit met majority of its goals and it was a great start. Microsoft has graciously made majority of the contents available online, and the videos for over 300 sessions can be seen on MSIgnite Youtube Channel.
After an excellent inaugural day, the Data Science Summit's day 2 kicked-off with the keynote by Featured Speaker Dr. Edward Tufte. Edward Tufte is a statistician and artist, and Professor Emeritus of Political Science, Statistics, and Computer Science at Yale University. He wrote, designed, and 4 classic books on data visualization. The New York Times described ET as the "Leonardo da Vinci of data," and Business Week as the "Galileo of graphics." He is just amazing to listen to and I plan to do a detailed post on his presentation later during the week.

The keynote was followed by Instructor-Led & Self-Paced Labs + Breakout Sessions,. I attended Omid Afnan's session on Go Big (with Data Lake Architecture) or Go Home! with the following abstract:
What can you do about information overload? IT professionals have to keep track of endless numbers of data streams from sources that seem to multiply every day. Web apps, social media, IoT devices, customer activity, and many more sources pump new data into the organization, even as pre-existing relational databases grow to keep up with business. Learn from professionals who have had to solve for these and similar problems. You'll see typical architectures using relational and non-relational, structured and unstructured, operational and analytic data—all working together to keep you sane. You'll also learn how Azure technologies can significantly reduce your operational overhead.

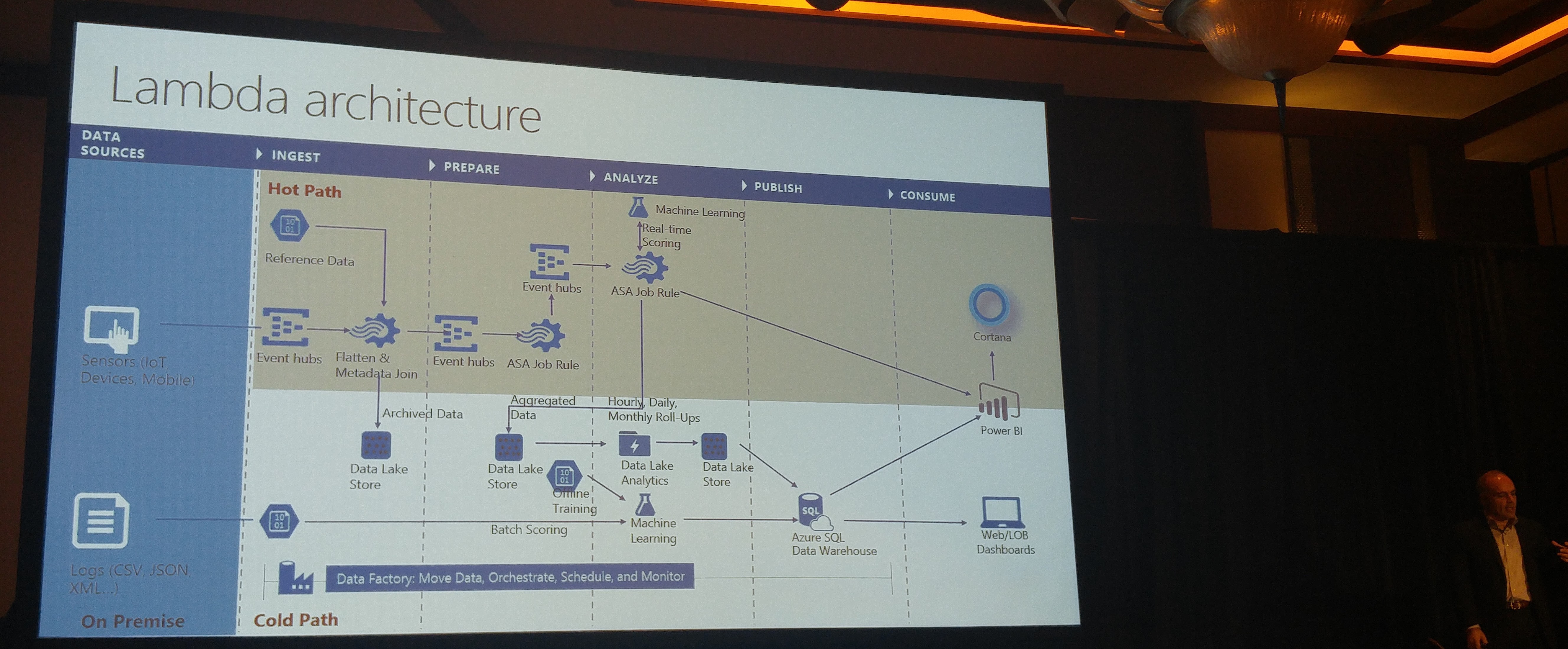
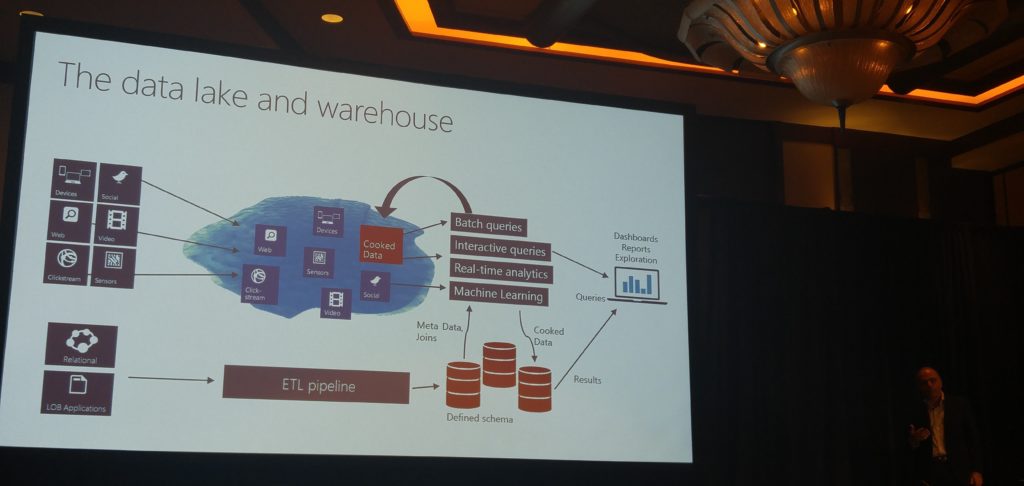
After this session Gokhan Uluderya, Nick Gaylord and Jack Shay talked about Build Real-World Analytics Solutions Combining Machine Learning with Human Intelligence:
By integrating scalable human judgment into your analytics solution, you can augment your lower-confidence machine learning predictions with accurate labels, and these labels can be used as additional training data to help improve your model. In this session, we’ll demonstrate how to build a real-world text analytics workflow using machine learning with humans in the loop.

Which was then followed by Maxim Lukiyanov's talk on Big, Fast, and Data-Furious…with Spark
Making teams of data scientists productive is a challenging task. The size of the data in Big Data problems is the first great hindrance to productivity. Apache Spark provides a foundation for the solution to this problem by offering interactive compute engine, but it is not sufficient in itself. In this session we review how a set of open source tools including Jupyter and Livy can be combined with advanced resource management and elasticity of Azure cloud to provide a comprehensive interactive platform for Big Data.

One of the most anticipated session was Frank Seide, CNTK (Computational Network Toolkit): Microsoft’s Open Source Deep Learning Toolkit
This talk introduces CNTK, Microsoft’s cutting-edge deep learning toolkit. CNTK is Microsoft's open-source computation-graph based deep learning toolkit used to train and evaluate deep neural networks used in Microsoft products, such as the Cortana speech models. CNTK supports feed-forward, convolutional, and recurrent networks for speech, image, and text workloads, also in combination. Popular network types are supported either natively (convolution) or can be described as a CNTK configuration (LSTM). CNTK scales to multiple GPU servers and is designed around efficiency. Attendees will learn how CNTK may address their deep learning needs, what they can/cannot do, how would a typical use look like, and how it works/what algorithms it implements.

The expo was quite good as well. Caught IBM's Agile session and found it to be quite interesting.

Also attended the data science curriculum EDX session along with Instructor-Led Lab: The Cortana Intelligence Suite - Part One: Foundations The Cortana Intelligence Suite - Part Two: Deep Dive and Self-Paced Lab: Python on Microsoft Notebooks – From the Basics to Data Science and Beyond

and it gave me some time to try out Developer's version of its HoloLens VR headset ( technically it's a MR (Mixed reality) or AR (Augmented reality) headset - VR is the vive or oculus)

{kind=link}
{kind=link}
To sum it all up, I found that Microsoft Machine Learning and Data Science Summit 2016 allowed myself and other attendees to learn and network Microsoft’s data scientists and big data engineers, learn how to apply machine learning & data science techniques to specific domain, and get architectural guidance & hands-on training to operationalize solutions at scale.
One thing I missed at the summit was that it was product focused; and the research aspect as in papers and posters was missing. This is an opportunity to improve upon. It makes sense to conclude these notes with the following.
The data may not contain the answer. And, if you torture the data long enough, it will tell you anything ~JW Tuke
